title:
keyword:
description:
art_id:
10378468
page_id:
595650
page_url:
/ai-model/what-is-google-gemini.html
content:
什么是 Gemini
谈到人工智能(AI),就不可能绕过正在重塑这一领域的巨头之一:Gemini。Gemini 标志着谷歌大胆进军 AI 新时代,而这股浪潮正在迅速改变从搜索方式到内容创作的一切。
如果你不想在这波趋势中掉队,不妨先从了解谷歌 Gemini 到底是什么开始。

Gemini(前身为 Bard)是谷歌最新推出的一系列 AI 模型,旨在同时处理多种类型的信息。与只能处理文本的标准大语言模型(LLM)不同,Gemini 是一个多模态系统,这意味着它不仅能理解文本,还能处理并生成图像、音频、视频,甚至代码等内容。
由于 “Gemini” 在谷歌 AI 生态中并不只指代单一产品,所以当人们搜索什么是 Gemini AI时,往往会发现这个名称会根据不同语境对应不同的产品形态。
- Gemini:为谷歌各类应用、产品与开发者工具提供支持的多模态 AI 模型家族。
- 谷歌基于这些模型打造的聊天机器人界面,取代了 Bard,同时也支持图像生成。
- 正在逐步登陆 Android 手机(尤其是 Google Pixel)、Wear OS 手表、Android Auto 与 Google TV 的新一代 AI 助手。
- 面向 Google Workspace 的 Gemini,可为 Gmail、Docs、Sheets、Slides 等付费 Workspace 工具提供 AI 辅助能力。
随着谷歌不断将 Gemini 融入几乎所有产品,从技术上看,这些都可以归入 Gemini 的范畴。不过,在谷歌不断扩张的 AI 生态中,每个工具仍然承担着不同的角色。
Google Gemini 模型:
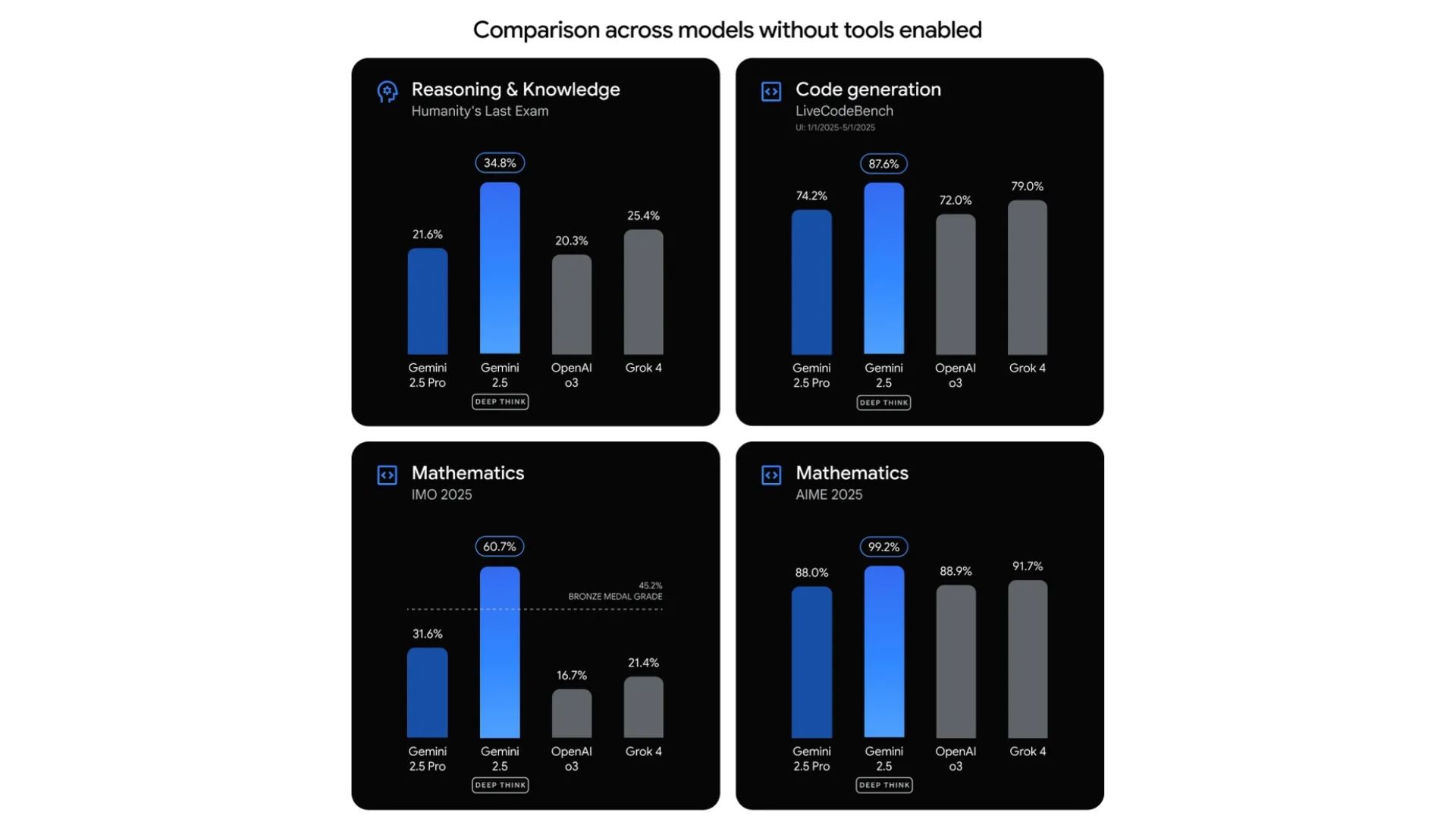
截至目前,Gemini 已发展到 2.5 代,而 Gemini 3.0 也传闻即将到来。Gemini 2.5 系列最核心的升级之一,就是引入了更强的推理能力,谷歌将其称为 “thinking(思考)”。
这一系列目前分为多个模型层级,不过这套分层也会随着谷歌的更新不断调整。其主要差异通常取决于参数规模,而参数规模会直接影响模型处理复杂任务的能力。
- Gemini 2.5 Pro:谷歌当前最强大的旗舰模型,适合深度推理、复杂问题求解和高级代码任务。它更强调准确性与分析深度,而非单纯追求速度。尤其擅长多步骤逻辑推理、处理大规模数据集(最高可达 100 万 token)以及多模态分析(文本、图像、音频、视频)。
- Gemini 2.5 Flash:该系列中速度快、效率高的模型。在保持强劲性能的同时,它针对高吞吐、低延迟、强调速度与成本效益的任务进行了优化。
- Gemini 2.5 Flash Image(又名 “Nano Banana”):这是专门用于高质量图像生成与编辑的模型。它延续了 Flash 的速度优势,同时加强了基于提示词的图像编辑、跨生成角色一致性以及多图融合等能力。
- Gemini 2.5 Flash-Lite:该家族中成本效率最高、速度最快的版本,主要面向超低延迟、高并发、以效率为优先的任务。它提供轻量级推理能力,非常适合高体量、相对简单的运营类工作负载。
| 模型 | Pro | Flash | Flash Image | Flash-Lite |
| 多模态输入 | 文本、代码、图像、视频、音频、PDF | 文本、代码、JSON | 文本、图像、代码、PDF | 文本、代码、图像、视频、音频、PDF |
| 输出类型 | 文本、代码、JSON | 文本、代码、JSON | 图像、文本 | 文本、代码、JSON |
| 用途定位 | 最强推理能力;复杂问题解决;高级编码;深度分析。 | 适合日常高容量任务;聊天应用;内容摘要等。 | 适合快速创意工作流;高质量、基于提示词的图像生成与编辑。 | 适合高体量、低成本任务;分类、简单路由、低延迟批处理。 |
| 思考模式 | ✅ | ✅ | ❌ | ❌ |
| 相对速度 | 较慢 | 快 | 快 | 最快 |
早期 Gemini 模型
在发展到现在之前,Gemini 还经历了数个早期版本,而这些版本也一步步塑造了今天的系统形态。
- Gemini 1.0 Ultra:谷歌最早的旗舰级 Gemini 模型,专注于高强度多模态推理、复杂任务与高级问题解决。
- Gemini 1.0 Nano:体量最小、效率最高的版本,专门面向端侧运行而设计,可直接为智能手机(如 Pixel)和其他设备提供功能支持。
- Gemini 1.5 Pro 和 1.5 Flash:这一代模型带来了突破性的性能提升。Pro 是拥有超大上下文窗口的强大全能模型,而 1.5 Flash 则是更轻量、更快速的版本。
Gemini 的核心功能与特性
如果你想知道 Gemini 应用究竟能做什么,答案是:很多。下面这些,就是 Gemini AI 最常见、也最实用的能力:




技术规格
为了处理复杂的多模态任务,Gemini 基于大规模多语言、多模态数据集进行训练,并依托 Google DeepMind 与 Google Research 多年的研发积累。其主要技术规格如下:
- 模型类型:基于 Transformer 的大语言模型(LLM)
- 训练数据:750 GB 数据(约 1.56 万亿个词)
- 可用入口:Gemini App、Google Workspace、Gemini API(Google AI Studio)以及 Vertex AI(Google Cloud)
- 上下文窗口:最高可达 100 万 token(token 可理解为文本片段,例如一个单词或词的一部分)
应用场景 - 何时/何处使用 Gemini
由于 Gemini 是一个能够处理多种媒体内容的多模态 AI 模型,因此它的应用场景覆盖了许多行业,具体取决于你希望如何使用它。
Gemini 常见应用方向
- 营销与广告:Gemini 能在多个层面为营销团队提供支持,从生成博客选题、撰写文案,到制作定制化视觉内容都可以参与。
一个很好的例子是为健康汽水品牌 Slice 打造的 “impossible ad(不可能广告)”。BarkleyOKRP 利用 Gemini 2.5 Pro 以及谷歌的生成式媒体工具,搭建了一个完整的 AI 驱动复古广播电台。其流程如下:
- Gemini 负责撰写 80/90 年代风格的歌词、角色故事和 DJ 台词。
- Imagen 和 Veo 负责画面视觉。
- Lyria 生成 lo-fi 背景音乐。
- Chirp 生成广播人声。
- 教育与培训:教育者、学生与行政人员都可借助 Gemini 提高备课效率、拓展创意思路,并更有信心地开展学习与教学。它可以帮助生成教案、适配不同学习水平的材料,并在几分钟内生成测验或练习活动。
在美国,已有超过 1,000 所高等教育机构将 Gemini for Education 融入学术与行政系统之中。
- 社交媒体内容创作:我们已经看到不少创作者借助 Gemini 推动内容走红。其多模态能力,正是这些爆款趋势背后的核心驱动力之一。
很多人会利用谷歌 Gemini 加速头脑风暴流程,从而快速测试数十种视觉想法、脚本与营销活动,直到找到最有潜力出圈的创意方向。
使用 Google Gemini 创作爆款内容的案例
由于 Google Gemini 很常被用于图像生成与编辑,多个 “Nano Banana 趋势” 已经在网上迅速走红。现在,即使没有高级修图技能或复杂编辑工具,普通用户也能在几秒内完成图像重塑与风格转换。



使用 Gemini 的提示词技巧
对于 Gemini 这样的多模态 AI 模型来说,提示词是所有创作的基础。如果提示词不够清晰,结果往往就容易跑偏。不过,只要掌握一些简单方法,你就能写出更好的提示词,并更有效地引导 Gemini 输出你想要的结果:
| 技巧 1:表达自然。 你不需要用过于正式的语句,Gemini 也能理解你。只要像平时说话那样输入,它通常也能准确执行你的指令。 |
| 技巧 2:简单直接。 清晰的指令效果最好。如果一句话可能被理解成多种意思,就应该重新改写,尽量避免歧义。 |
| 技巧 3:补充上下文并使用强相关关键词。 你提供的背景越完整,Gemini 越容易理解你的目标。适当地加入关键词,也有助于它抓住重点并朝正确方向输出。 |
| 技巧 4:把复杂任务拆成更小步骤。 如果你要完成多项任务,建议分开逐条发送。这样更利于 Gemini 保持聚焦,也方便你逐步微调结果。 |
| 技巧 5:做图像生成时要说明艺术风格。 当你生成图片时,应尽量具体说明想要的风格,比如超写实、电影感、动漫、复古、赛博朋克等。描述越明确,结果越接近你的想象。 |
需要注意的局限性
尽管 Gemini 的表现已经相当出色,但它仍有一些需要留意的限制。
像 Gemini 这样的 LLM 天生就有“幻觉”倾向。它可能生成听起来权威、像真的一样的内容,但其中的信息实际上可能是错误的、无意义的,甚至完全虚构。
Gemini 的训练数据来源于大量人类生成内容,因此也会继承其中已有的偏见。为了让输出在不同人群中尽可能公平、合乎伦理,就需要持续进行偏见治理。
Gemini 并不具备真正的人类直觉或现实常识。因此,当任务需要依赖真实生活经验时,它的表现可能会受到限制,甚至出现判断错误。
虽然模型的输出看起来很有创造力,但其本质仍然基于既有训练数据中的模式学习。因此,在需要真正原创、完全跳脱既有框架的内容时,它可能仍有局限。
实操工作流 - 如何与万兴喵影配合使用
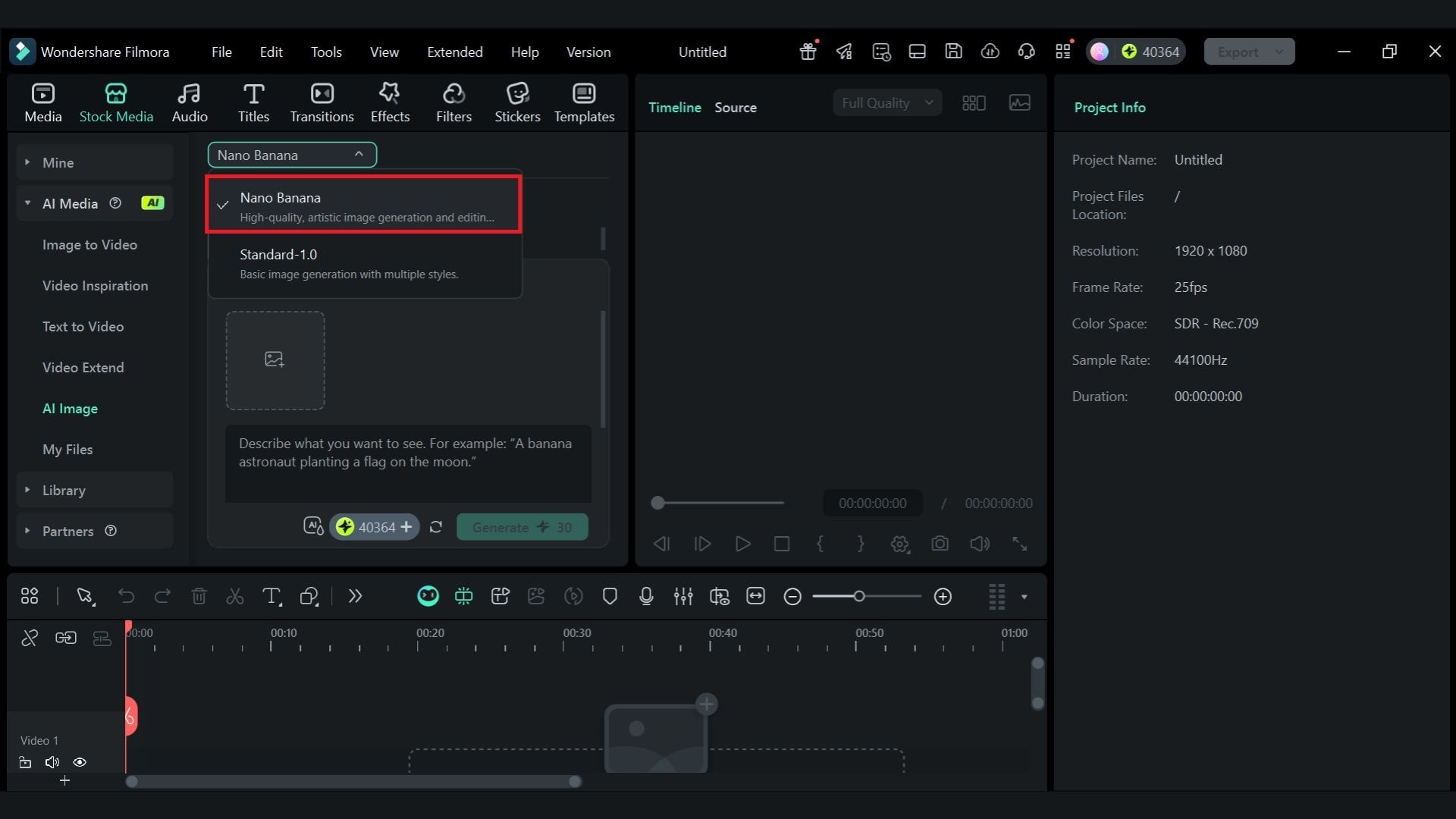
现在,你已经可以直接在Nano Banana模型基础上,通过万兴喵影生成图像。这比单独在 Gemini 平台上操作更高效,也更灵活。
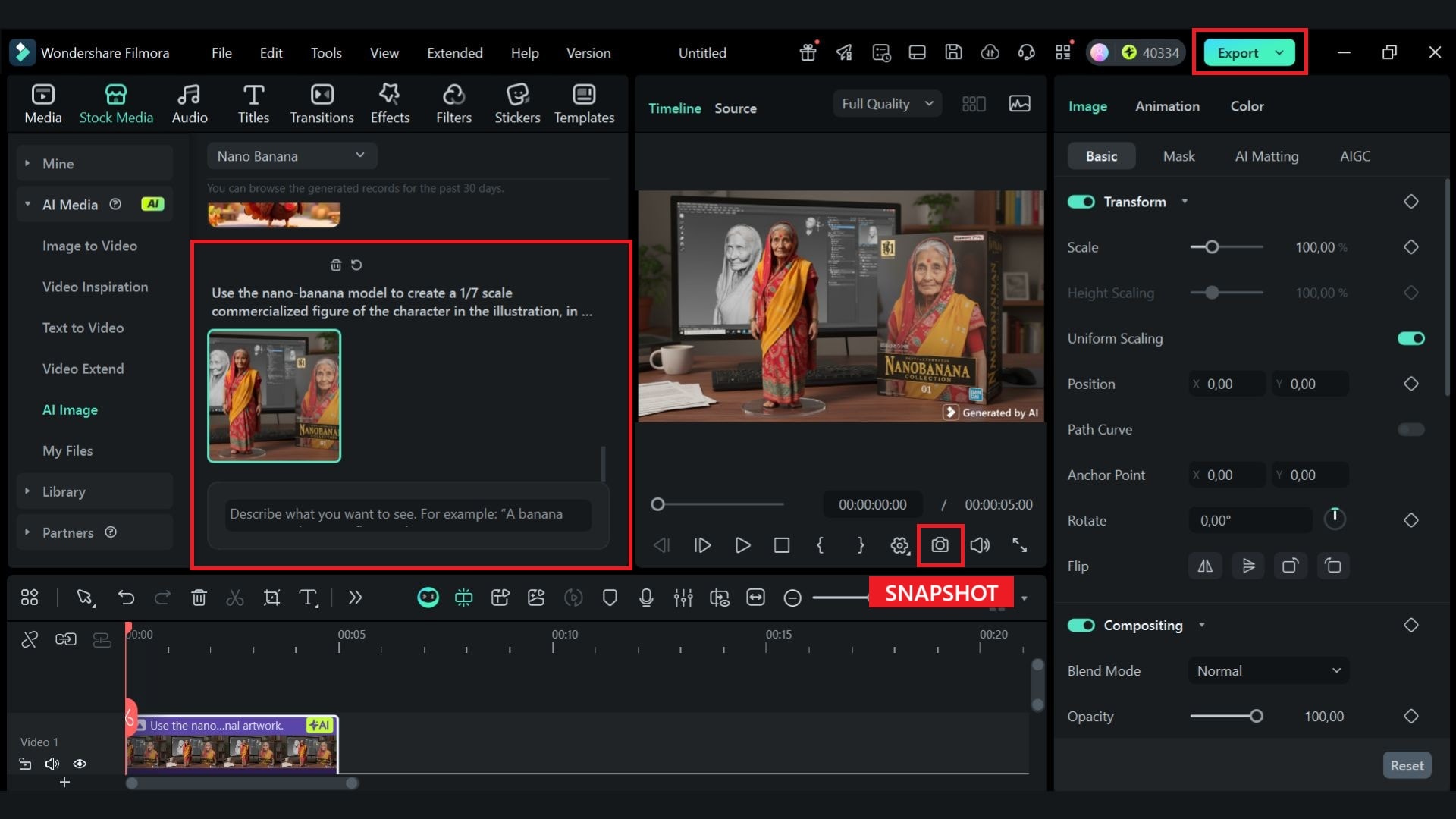
在万兴喵影中,你可以生成图片后立刻继续优化,无需在不同应用之间来回切换。你可以直接调色、裁剪、添加标题、叠加特效,或者把它融入完整的视频时间线中。
这样的工作方式可以省去从 Gemini 下载素材、再重新上传到剪辑器中的来回折腾。你不必担心反复导入导出带来的效率损耗。万兴喵影将整个流程整合在同一套工作流内,图像生成后,你可以立刻增强画面、添加动效,甚至围绕它构建完整场景。
除了使用 Nano Banana 生成图像外,你还可以借助万兴喵影的 AI 图片转视频 功能(由谷歌 Gemini 视频生成模型 Veo 3 提供支持),把静态图片进一步转换为视频。
如何在万兴喵影中使用 Nano Banana 生成图像